What I've learned from hosting the ML Engineered podcast (PLUS: the research area you NEED to know about, data science project management, and more...)
I mentioned last week that I had to skip an episode release because of guest reschedulings. Since then, I’ve recorded five episodes, which was fun but extremely tiring. Rest assured, I won’t be missing another release!
Also, in case you missed it, I wrote up a study guide for aspiring ML engineers that lays out a clear starting path and contains a list of resources that I and my friends have learned from.
| Read the Study Guide |
In this week's edition:
- My Interview on the MLOps Community podcast
- An EPIC blog post on self-supervised representation learning
- A Better Way to Manage Data Science Projects
- 3000+ ML datasets now available in one place
- The Past, Present, and Future of Big Data
My Interview on the MLOps Community podcast
 |
Demetrios and Vishnu from the ML Ops Community were kind enough to invite me onto their Coffee Sessions podcast. We discussed my experience working as an ML engineer and starting the podcast, lessons learned from talking to experts, and trends we’ve noticed in the industry.
Click here to listen to the episode, or find it in your podcast player of choice: https://www.mlengineered.com/listen
Vishnu also wrote up some of the takeaways from episode, which you can find in their latest newsletter edition here.
I'd love to hear your thoughts on what we discussed--do you agree? disagree? Hit the reply button and let me know!
An EPIC blog post on self-supervised representation learning
“Self-supervised learning opens up a huge opportunity for better utilizing unlabelled data, while learning in a supervised learning manner. This post covers many interesting ideas of self-supervised learning tasks on images, videos, and control problems.”
Self-supervised learning has been producing breakthrough after breakthrough (BERT, GPT-3, CLIP), mostly in the field of NLP, by learning representations from unlabeled data that can then be fine-tuned for specific tasks where labeled data is available. But in the past few year or so, there’s been an explosion of research interest in applying these techniques to other ML domains.
In preparing for an upcoming podcast episode, I had to get up to speed to the state of the art in this area, and came across Lilian Weng’s fantastic blog post on the topic. She’s a research scientist at OpenAI and summarizes the contributions from a bunch of different papers with just the right amount of mathematical rigor and detail.
In many real-world problems, labeled data is a major bottleneck, and self-supervised learning is currently the most powerful way to get past it. I suspect that it will only become more important in the future. Read it here.
A Better Way to Manage Data Science Projects
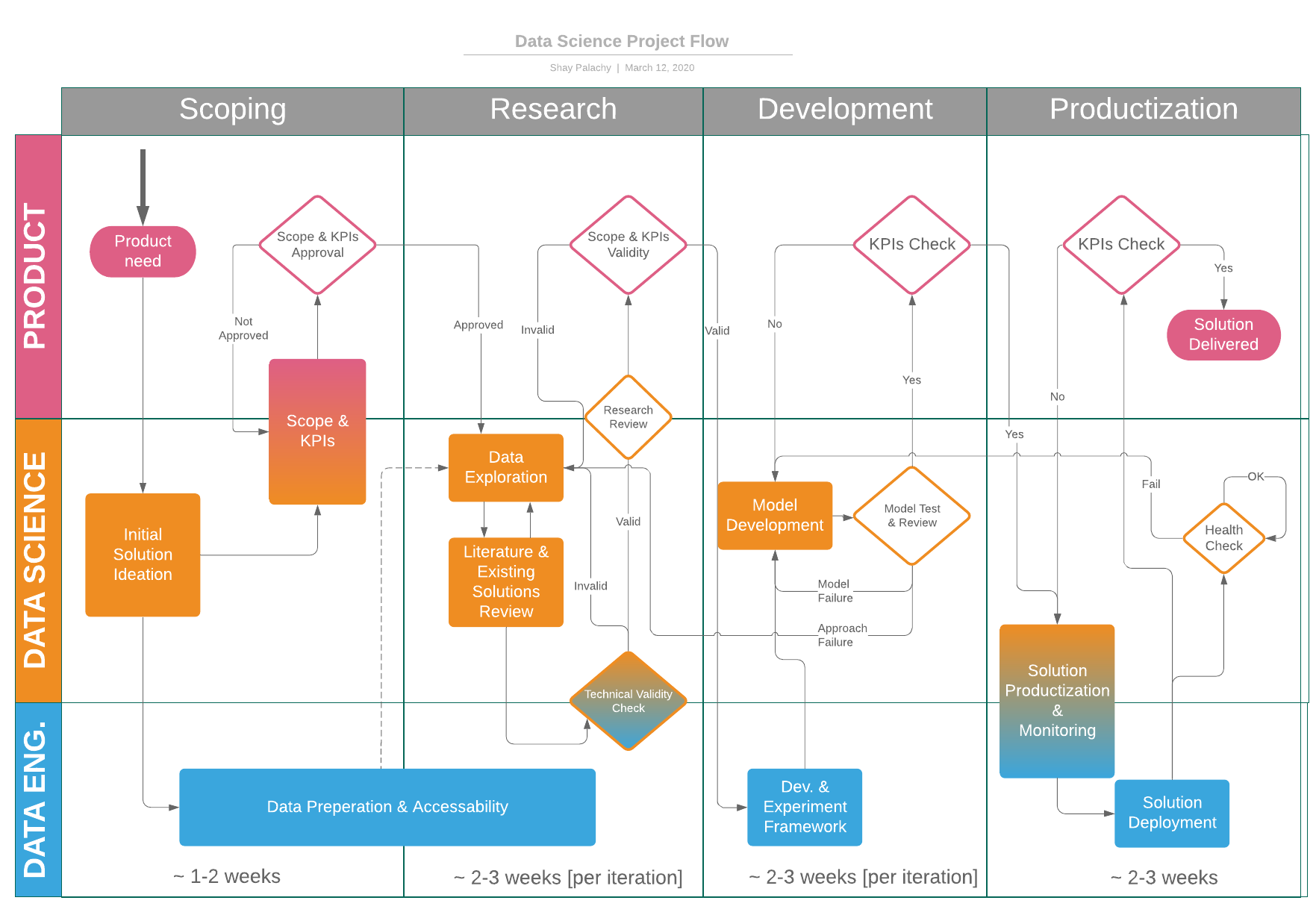 |
As I mentioned in the interview above, something I like to read a lot about is creating systems for successfully executing data science projects. I recently came this article from Shay Palachy, a consultant who’s worked with many different startups on their ML projects.
He breaks down the project flow into 4 distinct phases, each with multiple intermediate steps. I especially love the emphasis he places on peer review before each phase can be completed and definitely plan on pushing my team to implement more of these practices. I definitely recommend you check it out by clicking here.
And if you know of articles that cover ground similar to this one, please hit reply and let me know!
3000+ ML datasets now available in one place
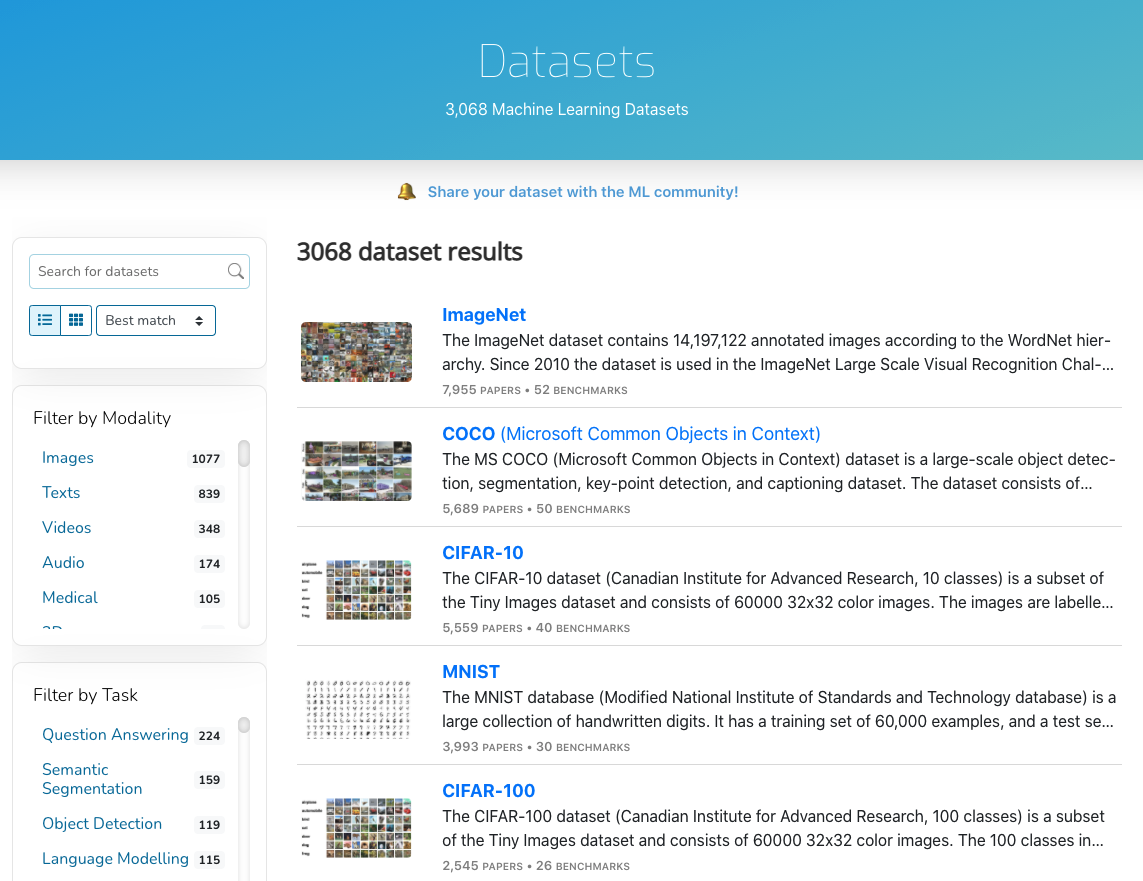 |
Papers with Code has started off 2021 very strong with the release of their excellent research newsletter and now a listing of nearly every ML dataset out there!
Also, if you haven’t yet seen their Methods Corpus, you should totally spend some time clicking around it. It’s basically Wikipedia for machine learning techniques. I find something new and interesting every time I visit it!
I have no idea what Papers with Code is going to release next, but at this rate, I’m sure it’s gonna be phenomenally useful.
The Past, Present, and Future of Big Data
Databricks recently raised $1B, valuing the company at $28B, which along with the massive Snowflake IPO, shows that enterprise adoption of big data is here to stay.
As part of their media tour, founder and CEO Ali Ghodsi went on one of my favorite podcasts, Invest Like the Best to talk about the history of distributed computing, Databrick’s founding story, and best practices for enterprise big data. You can listen by clicking here.
Pair with this a16z podcast interview on the Evolution of Data Architectures.
Machine Learning Engineered
There’s no podcast episode this week due to an unfortunate coincidence of multiple guests needing to reschedule. My apologies, I’ll be doing my best in the future to not let this happen again. That doesn’t mean I don’t have any new content for this week, though! Today I’m releasing an article that answers one of the most common questions I get: “I want to learn machine learning, where do I start / what do I do?” When I was first getting started in ML, it was pretty straightforward: there was...
After a month off from releasing original interviews on the podcast feed, I’m so excited to be sharing this episode with all of you! Aether Biomachines is one of the most interesting machine learning startups I’ve ever come across and I was thrilled to interview the founder, Pavle Jeremic. Building a Post-Scarcity Future using Machine Learning “How can we make sure that the economy is so productive that the desperation that leads people to commit atrocities never happens?” In this episode,...

First, an apology: due to some technical issues, the release of the second “Best of ML Engineered in 2020” episode is delayed until this weekend. Sorry about that! Until then, you can check out last week’s compilation episode of the best ML engineering highlights: Click here to listen to the episode, or find it in your podcast player of choice: https://www.mlengineered.com/listen Onto this week’s newsletter! Evaluating online machine learning models “Batch models are meant to be used when you...